
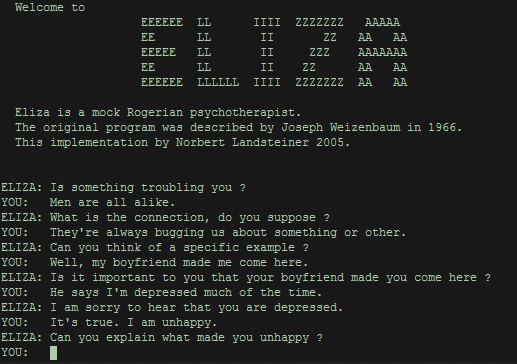
Schon lange nicht mehr hat eine Innovation der Informationstechnologie so viel Echo in den allgemeinen Medien erfahren wie die schreibende KI-Maschine ChatGPT. Leider erklären die Journalist:innen, die das Thema verbreiten, so gut wie nie, worum es sich tatsächlich handelt und wie dieser scheinbar intelligente Chatbot funktioniert. Altgediente Digisaurier können da helfen, denn sie haben schon in den Siebzigerjahren mit ELIZA gechattet.
Bereits 1966(!!!) hatte Joseph Weizenbaum, einer der Vordenker der Digitalisierung, ein Programm entwickeln lassen, das mit Menschen in natürlicher Sprache kommunizierte. Seine Idee war es, mit ELIZA erstmals den Turing-Test erfolgreich zu bestehen. Der geniale Alan Turing hatte postuliert, dass ein Computer dann als „intelligent“ zu betrachten ist, wenn ein Mensch bei der Kommunikation mit der Maschine nicht mit Sicherheit sagen könnte, ob sein Gegenüber ein Mensch oder ein Elektronenhirn sei.
Heute wissen wir, dass diese Aufgabe einen gewaltigen Haken hat und heutzutage nicht mehr brauchbar ist. Denn im Laufe der Jahrzehnte hat sich herausgestellt, dass die persönliche Erfahrung des Probanden mit Computern ausschlaggebend für das Ergebnis ist. Kurz gesagt: Ein mit Rechnern und Programmen bestens vertrauter Mensch wird mit seiner Antwort auf die Frage „Mensch oder Maschine?“ deutlich öfter richtig liegen als ein IT-Abstinenzler.
Das beweist die Debatte rund um ChatGPT momentan tagtäglich. Und diskutiert wird viel, auch von Menschen, die sich vorher für die KI nicht die Bohne interessierten. Denn für uns Digisaurier sind Anwendungen wie der Chatbot von OpenAI beinahe schon alte Hüte. Und weil wir ELIZA kennen und schon seit vielen Jahren mit Alexa, Cortana, Siri und den anderen „digitalen Assistenten“ schwätzen, erkennen wir mit wenig Mühe, wen wir da vor uns haben.
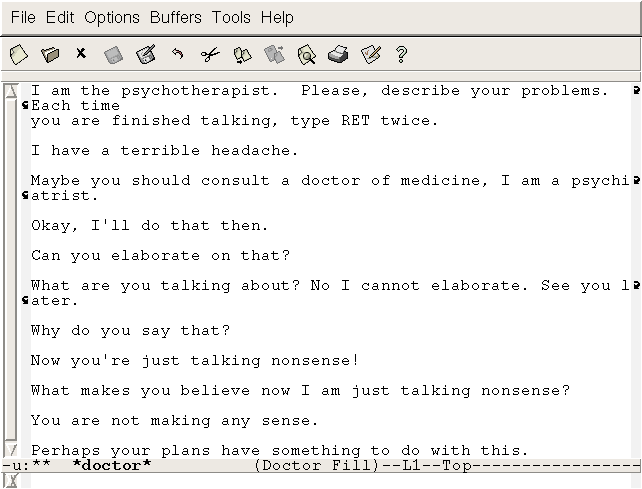
Denn natürlich beherrschen diese Systeme die sogenannte „natürliche Sprache“ nicht, sondern imitieren dieses Verständnis auf der Basis riesiger Datenbestände und vergleichsweise einfacher Algorithmen. Die waren schon Grundlage von ELIZA. Das Programm, das einen Psychiater der klientenzentrierten Methode – wie sie der Amerikaner Carl Rogers in den Dreißigerjahren entwickelt hatte, nachahmt, zerlegt die vom Probanden eingegebene Frage in einzelne Wörter. Die gleicht es mit einem Thesaurus (einer Wörterdatenbank) ab, in dem Synonym und Zusammenhänge gespeichert sind. Aus den gefundenen Wörtern und deren Kontext ensteht dann die Reaktion der ELIZA – in aller Regel eine Frage oder eine Phrase.
Die simpelste Form der Reaktion ist es, die Frage als Behauptung zu wiederholen. Gibt der Klient „Mir geht es heute nicht gut.“ ein, antwortet ELIZA schlicht „Warum geht es dir heute nicht gut.“ Böse Zungen behaupten, Psychiater täten auch nichts anderes… In den ersten Versionen konnte das Programm auch nicht viel anders. Je mehr Wörter aber erfasst wurden und je mehr Zusammenhänge in der Datenbank definiert waren, umso schlauer wurde ELIZA. So fragte sie „Und wie ist dein Verhältnis zu deinen anderen Familienmitgliedern?“, wenn der Klient etwas über den eigenen Vater geäußert hatte.
Übrigens: ELIZA ist noch heute in einer recht fortgeschrittenen und 2001 web-gerecht gestalteten Version online, sodass sich jeder von der künstlichen Intelligenz dieses uralten Beispiels für einen Chatbot überzeugen kann.
Die sogenannte „natürliche Sprache“ eines Menschen zu „verstehen“, ist für ein digitales System eine leichte Übung. Das hat seinerzeit schon das Datenbankprogramm Q&A (Question & Answer, auf Deutsch als F&A angeboten) in den Achtzigerjahren bewiesen. Statt abstrakte Befehlsketten wie bei einer SQL- oder dBase-Abfrage erlernen zu müssen, erlaubte es die Anwendung, Sätze in natürlicher Sprache einzugeben. Wollte man von einer Personendatenbank die Zahl der Leute in einem bestimmten Ort wissen, gab man einfach ein „Wie viele Menschen leben in Düsseldorf?“ Die Ausgabe war dann auch schon in eine verständliche Form gekleidet: „In Düsseldorf leben 547 in der Datenbank verzeichnete Personen.“ In späteren Versionen ließen sich Datenbank mit Anforderungen in natürlicher Sprache erstellen, befüllen und verändern.
Grundlage sind bis heute möglichst umfangreiche Wortverzeichnisse samt der grammatischen Regeln einer Sprache, mit denen Nomen dekliniert und Verben konjugiert werden sowie Tabellen, in denen die Verknüpfungen, die Verbindungen der Wortbedeutungen verzeichnet sind. Beides ist Handarbeit. Deshalb steht das „GPT“ in ChatGPT auch für „Generative Pre-trained Transformer“, wobei „pre-Trained“ genau das meint: Menschen haben das System mit Wörtern und Sinn befüllt. Übrigens in der Regel in Niedriglohnländern zu Hungerlöhnen.
Der Fortschritt, den wir Google verdanken, ist der verwendete Transformer, der dem, was ELIZA und Q&A konnten, meilenweit überlegen ist. Entstanden sind solche Transformer im Zusammenhang mit maschinellen Übersetzern, denn „transformieren“ heißt in diesem Zusammenhang, dass eine Folge von Zeichen automatisch in eine andere Folge von Zeichen übertragen werden kann – ein Wort in englischer Sprache beispielsweise in ein deutsches Wort. Der Google-Übersetzer war einer der ersten, der auch komplexe Sätze von einer in eine andere Sprache übersetzen konnte. Technologisch wurde er längst von der deutschen Entwicklung namens DeepL überholt, die nicht bloß richtige Übersetzungen liefert, sondern auch die kulturellen Unterschiede berücksichtigt.
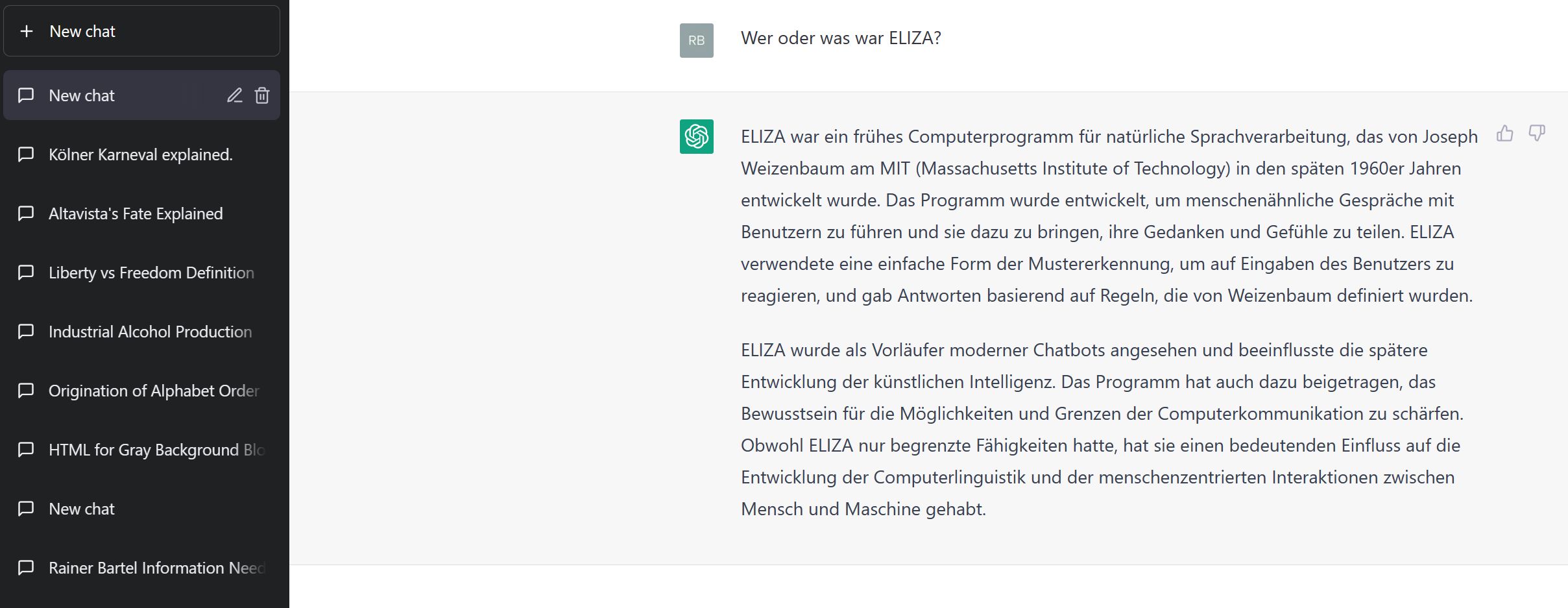
Das sagt ChatGPT über ELIZA:
ELIZA war ein frühes Computerprogramm für natürliche Sprachverarbeitung, das von Joseph Weizenbaum am MIT (Massachusetts Institute of Technology) in den späten 1960er Jahren entwickelt wurde. Das Programm wurde entwickelt, um menschenähnliche Gespräche mit Benutzern zu führen und sie dazu zu bringen, ihre Gedanken und Gefühle zu teilen. ELIZA verwendete eine einfache Form der Mustererkennung, um auf Eingaben des Benutzers zu reagieren, und gab Antworten basierend auf Regeln, die von Weizenbaum definiert wurden.ELIZA wurde als Vorläufer moderner Chatbots angesehen und beeinflusste die spätere Entwicklung der künstlichen Intelligenz. Das Programm hat auch dazu beigetragen, das Bewusstsein für die Möglichkeiten und Grenzen der Computerkommunikation zu schärfen. Obwohl ELIZA nur begrenzte Fähigkeiten hatte, hat sie einen bedeutenden Einfluss auf die Entwicklung der Computerlinguistik und der menschenzentrierten Interaktionen zwischen Mensch und Maschine gehabt.
Das „Pre“ in „pre-trained“ zeigt an, dass mit der Eingabe von Daten durch Menschen die Arbeit nicht getan ist; es handelt sich sozusagen nur um das erste Training, das keinerlei Intelligenz erzeugt. Das System weiß nicht, was ein Ball ist, wenn ihm dieses Wort geschenkt wird, mangels physischer Sensoren kann es sich keine Vorstellung von einem Ball machen. Also müssen Menschen ihm sagen, was einen Ball ausmacht („rund“, „elastisch“ etc.) und was man mit ihm anstellt. Stellt der menschliche Trainer die Verbindung zwischen diesem Wort und zum Beispiel dem Fußballsport her, ist der Transformer schon schlauer.
Und auf Basis dieser Schläue beginnt er selbst, Verbindungen herzustellen, Sinnzusammenhänge zu kreieren, sogar zwischen Worten, deren gemeinsamen Kontext man ihm nicht beigebracht hat. Und damit betreten wir das weite Feld des maschinellen Lernens. Haben Tippsklaven das System mit ausreichend vielen Begriffen und Zusammenhängen gefüttert, machen sich komplexere Algorithmen ans Werk und schaffen in neuronalen Netzen eigene Zusammenhänge. Bots flitzen durchs Netz und sammeln noch mehr Wörter, Sätze und Sinnzusammenhänge. Regeln, die über das Beigebrachte hinausgehen, entstehen, werden getestet und im Erfolgsfall übernommen.
Ziel ist es, dass nicht mehr „der Computer“ vorgibt, wie man gefälligst mit ihm zu kommunizieren hat, sondern „der Computer“ sich auf den geschriebenen oder gesprochenen Input des Menschen einstellt. Dem kamen schon ELIZA und Q&A recht nahe, aber ChatGPT und Konsorten sind auf dem Weg, das genannte Ziel final zu erreichen.